11 KiB
![]()
| English | 简体中文 |
Overview • Architecture • Key Features • Getting Started • API Reference • Developer Guide
💡 WeKnora - LLM-Powered Document Understanding & Retrieval Framework
📌 Overview
WeKnora is an LLM-powered framework designed for deep document understanding and semantic retrieval, especially for handling complex, heterogeneous documents.
It adopts a modular architecture that combines multimodal preprocessing, semantic vector indexing, intelligent retrieval, and large language model inference. At its core, WeKnora follows the RAG (Retrieval-Augmented Generation) paradigm, enabling high-quality, context-aware answers by combining relevant document chunks with model reasoning.
Website: https://weknora.weixin.qq.com
🏗️ Architecture
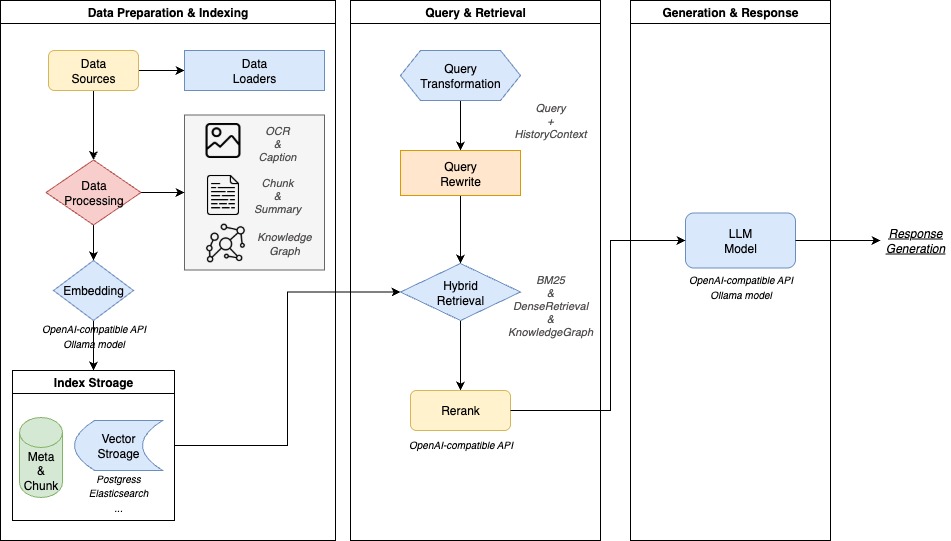
WeKnora employs a modern modular design to build a complete document understanding and retrieval pipeline. The system primarily includes document parsing, vector processing, retrieval engine, and large model inference as core modules, with each component being flexibly configurable and extendable.
🎯 Key Features
- 🔍 Precise Understanding: Structured content extraction from PDFs, Word documents, images and more into unified semantic views
- 🧠 Intelligent Reasoning: Leverages LLMs to understand document context and user intent for accurate Q&A and multi-turn conversations
- 🔧 Flexible Extension: All components from parsing and embedding to retrieval and generation are decoupled for easy customization
- ⚡ Efficient Retrieval: Hybrid retrieval strategies combining keywords, vectors, and knowledge graphs
- 🎯 User-Friendly: Intuitive web interface and standardized APIs for zero technical barriers
- 🔒 Secure & Controlled: Support for local deployment and private cloud, ensuring complete data sovereignty
📊 Application Scenarios
| Scenario | Applications | Core Value |
|---|---|---|
| Enterprise Knowledge Management | Internal document retrieval, policy Q&A, operation manual search | Improve knowledge discovery efficiency, reduce training costs |
| Academic Research Analysis | Paper retrieval, research report analysis, scholarly material organization | Accelerate literature review, assist research decisions |
| Product Technical Support | Product manual Q&A, technical documentation search, troubleshooting | Enhance customer service quality, reduce support burden |
| Legal & Compliance Review | Contract clause retrieval, regulatory policy search, case analysis | Improve compliance efficiency, reduce legal risks |
| Medical Knowledge Assistance | Medical literature retrieval, treatment guideline search, case analysis | Support clinical decisions, improve diagnosis quality |
🧩 Feature Matrix
| Module | Support | Description |
|---|---|---|
| Document Formats | ✅ PDF / Word / Txt / Markdown / Images (with OCR / Caption) | Support for structured and unstructured documents with text extraction from images |
| Embedding Models | ✅ Local models, BGE / GTE APIs, etc. | Customizable embedding models, compatible with local deployment and cloud vector generation APIs |
| Vector DB Integration | ✅ PostgreSQL (pgvector), Elasticsearch | Support for mainstream vector index backends, flexible switching for different retrieval scenarios |
| Retrieval Strategies | ✅ BM25 / Dense Retrieval / GraphRAG | Support for sparse/dense recall and knowledge graph-enhanced retrieval with customizable retrieve-rerank-generate pipelines |
| LLM Integration | ✅ Support for Qwen, DeepSeek, etc., with thinking/non-thinking mode switching | Compatible with local models (e.g., via Ollama) or external API services with flexible inference configuration |
| QA Capabilities | ✅ Context-aware, multi-turn dialogue, prompt templates | Support for complex semantic modeling, instruction control and chain-of-thought Q&A with configurable prompts and context windows |
| E2E Testing | ✅ Retrieval+generation process visualization and metric evaluation | End-to-end testing tools for evaluating recall hit rates, answer coverage, BLEU/ROUGE and other metrics |
| Deployment Modes | ✅ Support for local deployment / Docker images | Meets private, offline deployment and flexible operation requirements |
| User Interfaces | ✅ Web UI + RESTful API | Interactive interface and standard API endpoints, suitable for both developers and business users |
🚀 Getting Started
🛠 Prerequisites
Make sure the following tools are installed on your system:
📦 Installation
① Clone the repository
# Clone the main repository
git clone https://knowlege-lsxd.git
cd WeKnora
② Configure environment variables
# Copy example env file
cp .env.example .env
# Edit .env and set required values
# All variables are documented in the .env.example comments
③ Start the services
# Start all services (Ollama + backend containers)
./scripts/start_all.sh
# Or
make start-all
③ Start the services (backup)
# Start ollama services (Optional)
ollama serve > /dev/null 2>&1 &
# Start the service
docker compose up -d
④ Stop the services
./scripts/start_all.sh --stop
# Or
make stop-all
🌐 Access Services
Once started, services will be available at:
- Web UI:
http://localhost - Backend API:
http://localhost:8080 - Jaeger Tracing:
http://localhost:16686
🔌 Using WeChat Dialog Open Platform
WeKnora serves as the core technology framework for the WeChat Dialog Open Platform, providing a more convenient usage approach:
- Zero-code Deployment: Simply upload knowledge to quickly deploy intelligent Q&A services within the WeChat ecosystem, achieving an "ask and answer" experience
- Efficient Question Management: Support for categorized management of high-frequency questions, with rich data tools to ensure accurate, reliable, and easily maintainable answers
- WeChat Ecosystem Integration: Through the WeChat Dialog Open Platform, WeKnora's intelligent Q&A capabilities can be seamlessly integrated into WeChat Official Accounts, Mini Programs, and other WeChat scenarios, enhancing user interaction experiences
📱 Interface Showcase
Web UI Interface
Knowledge Upload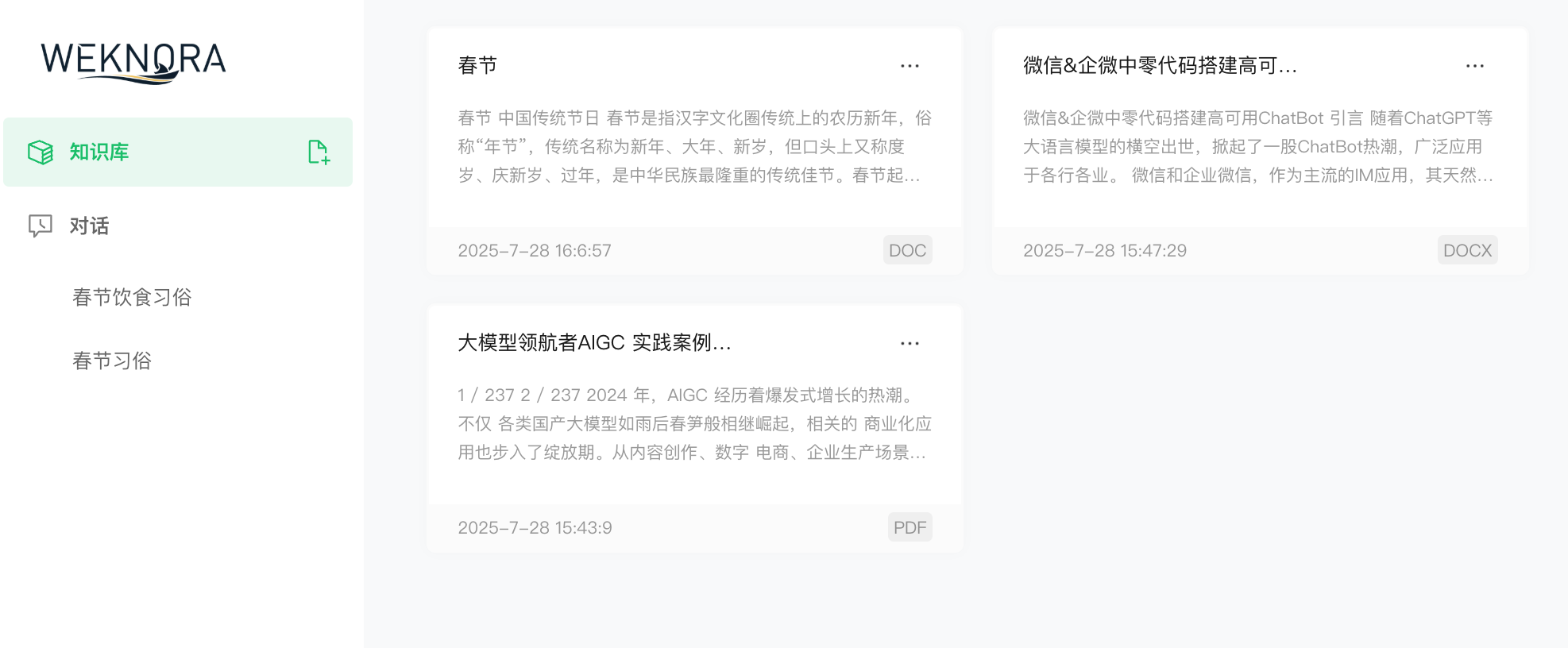 |
Q&A Entry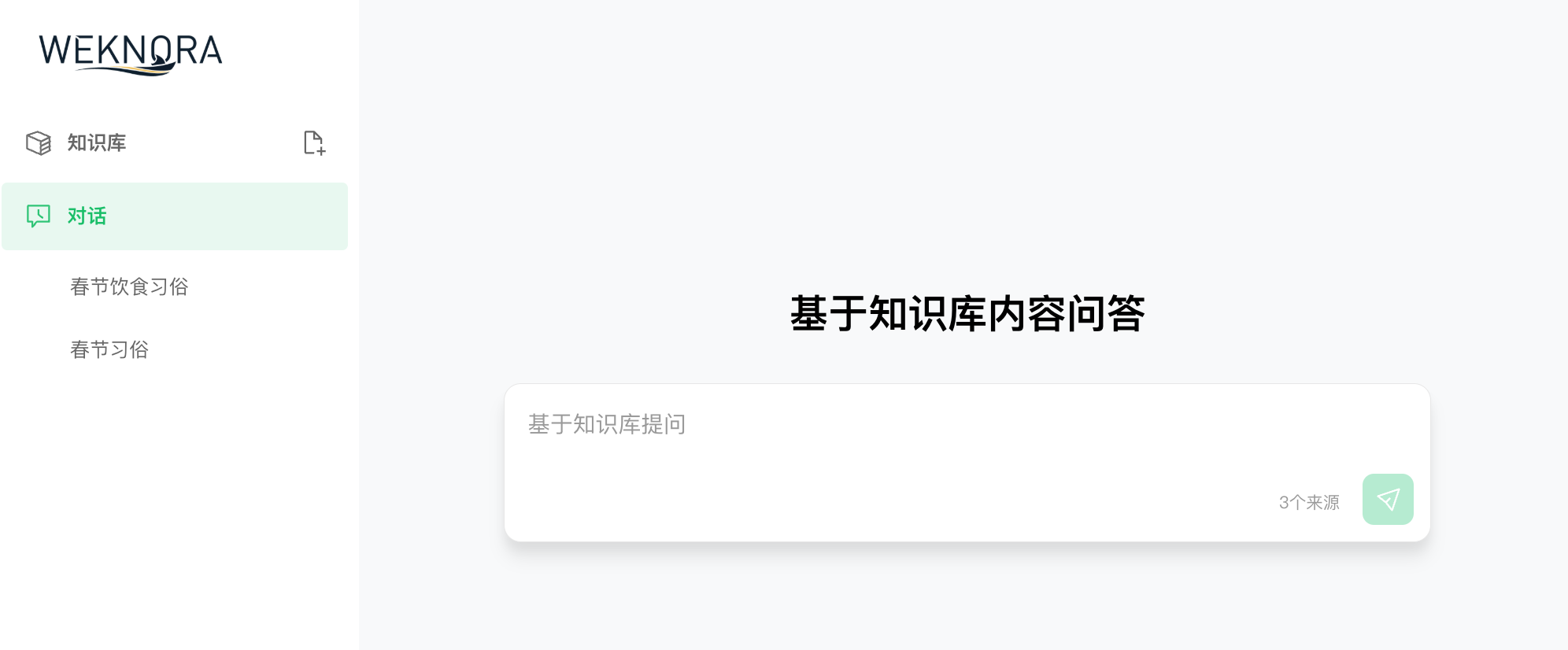 |
Rich Text & Image Responses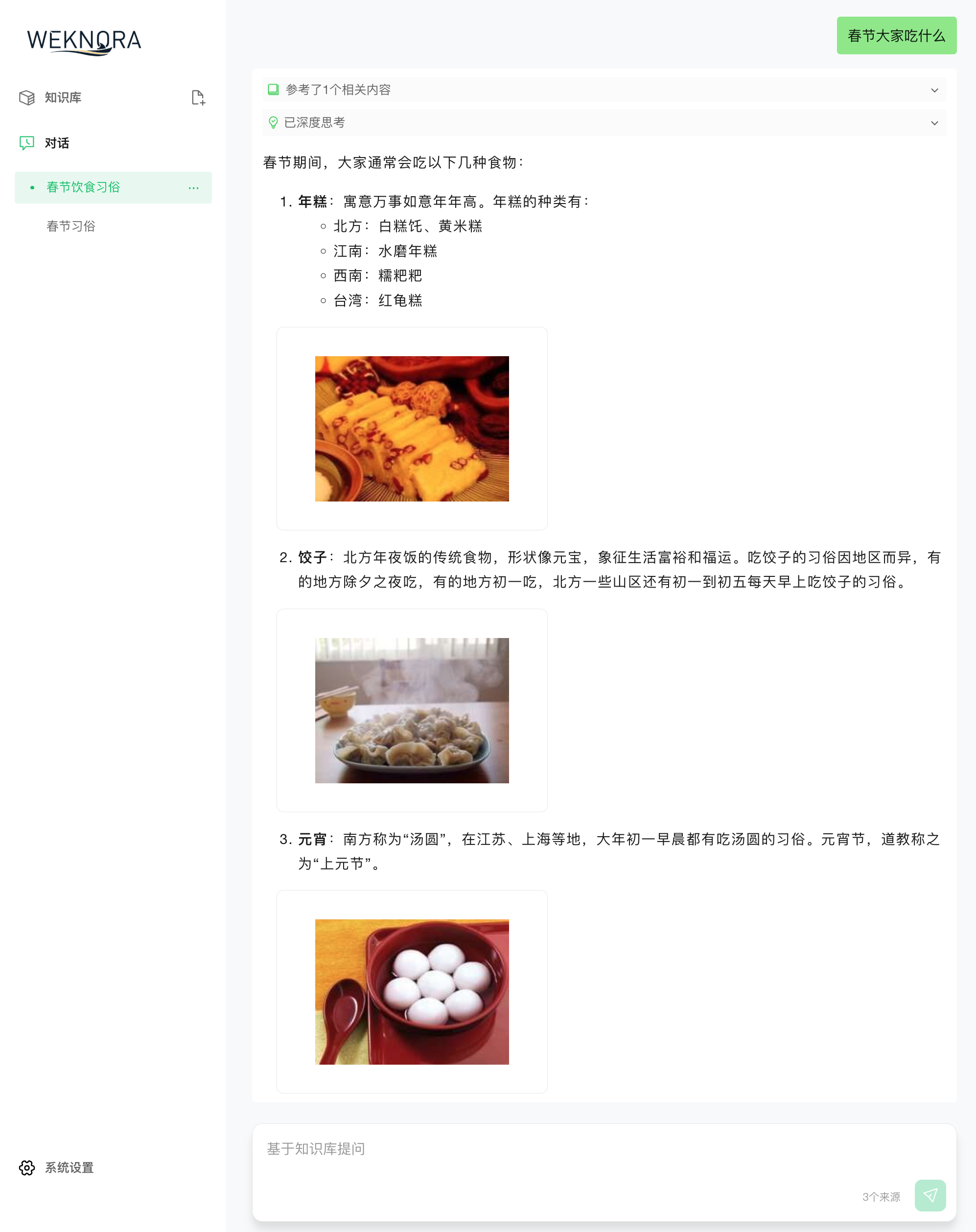 |
|
Knowledge Base Management: Support for dragging and dropping various documents, automatically identifying document structures and extracting core knowledge to establish indexes. The system clearly displays processing progress and document status, achieving efficient knowledge base management.
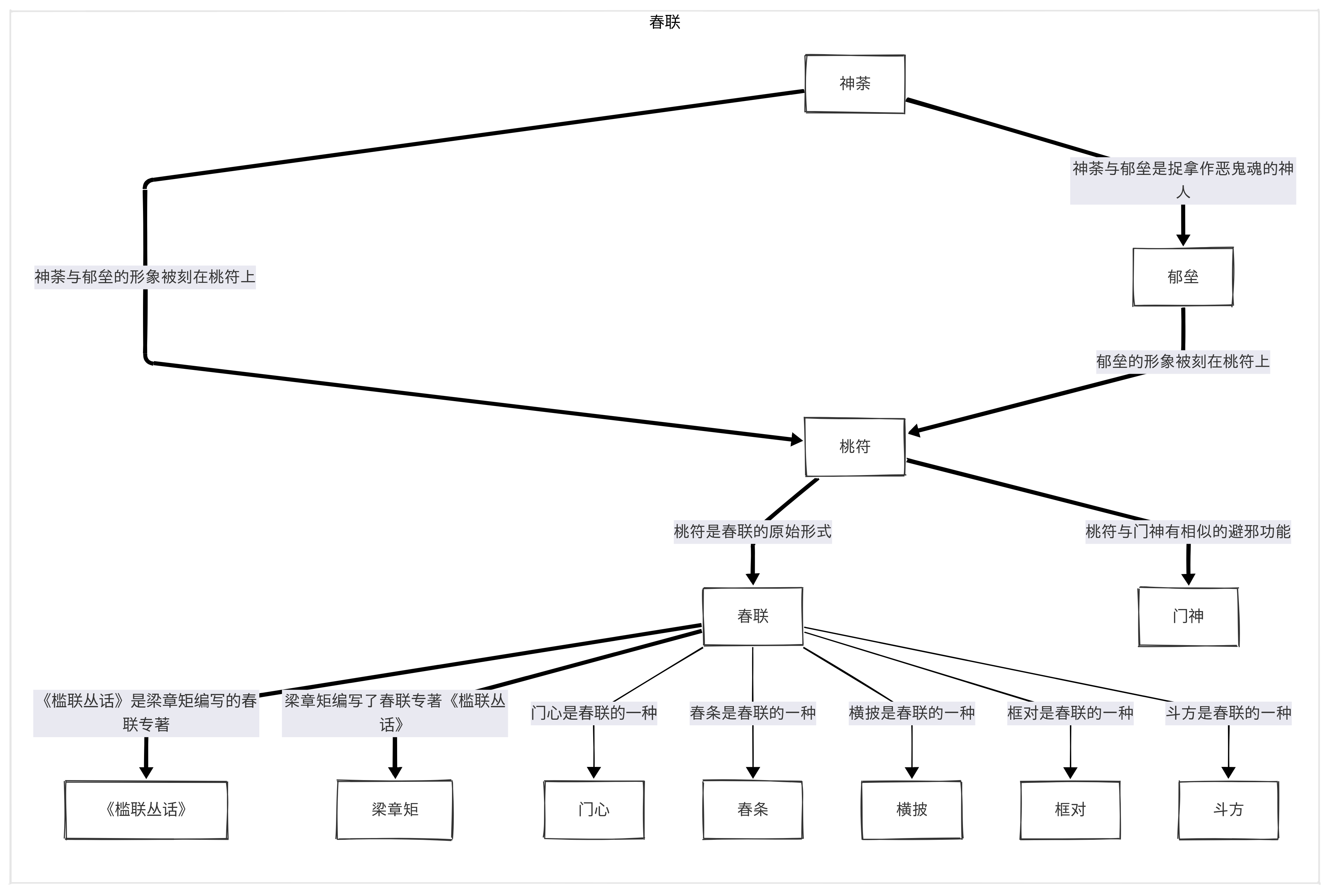
Document Knowledge Graph
 |
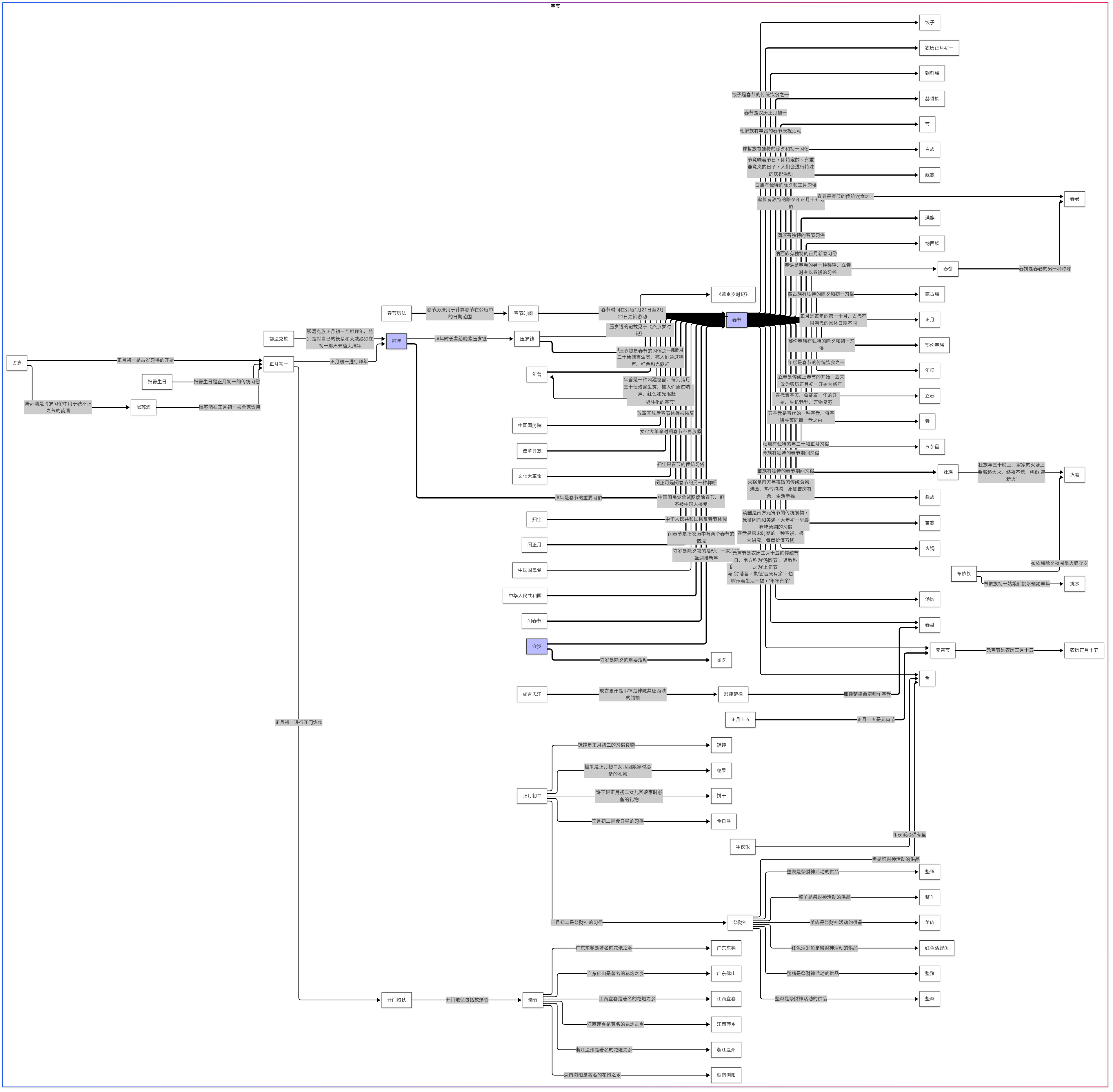 |
WeKnora supports transforming documents into knowledge graphs, displaying the relationships between different sections of the documents. Once the knowledge graph feature is enabled, the system analyzes and constructs an internal semantic association network that not only helps users understand document content but also provides structured support for indexing and retrieval, enhancing the relevance and breadth of search results.
📘 API Reference
Detailed API documentation is available at: API Docs
🧭 Developer Guide
📁 Directory Structure
WeKnora/
├── cmd/ # Main entry point
├── internal/ # Core business logic
├── config/ # Configuration files
├── migrations/ # DB migration scripts
├── scripts/ # Shell scripts
├── services/ # Microservice logic
├── frontend/ # Frontend app
└── docs/ # Project documentation
🔧 Common Commands
# Wipe all data from DB (use with caution)
make clean-db
🤝 Contributing
We welcome community contributions! For suggestions, bugs, or feature requests, please submit an Issue or directly create a Pull Request.
🎯 How to Contribute
- 🐛 Bug Fixes: Discover and fix system defects
- ✨ New Features: Propose and implement new capabilities
- 📚 Documentation: Improve project documentation
- 🧪 Test Cases: Write unit and integration tests
- 🎨 UI/UX Enhancements: Improve user interface and experience
📋 Contribution Process
- Fork the project to your GitHub account
- Create a feature branch
git checkout -b feature/amazing-feature - Commit changes
git commit -m 'Add amazing feature' - Push branch
git push origin feature/amazing-feature - Create a Pull Request with detailed description of changes
🎨 Code Standards
- Follow Go Code Review Comments
- Format code using
gofmt - Add necessary unit tests
- Update relevant documentation
📝 Commit Guidelines
Use Conventional Commits standard:
feat: Add document batch upload functionality
fix: Resolve vector retrieval precision issue
docs: Update API documentation
test: Add retrieval engine test cases
refactor: Restructure document parsing module
📄 License
This project is licensed under the MIT License. You are free to use, modify, and distribute the code with proper attribution.